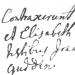 Leeshulp, transcriptie, vertaling, betekenis » Automatische transcriptie
Leeshulp, transcriptie, vertaling, betekenis » Automatische transcriptie


Bij het Nationaal Archief doet men momenteel proeven met een computerprogramma Transkribus, dat geschreven teksten transcribeert.
In het onderstaande voorbeeld een brief, geschreven door Johan de Witt.
@Moderator, het leek mij voor de belangstellenden het beste om dit bericht te plaatsen in het subforum Leeshulp in plaats van in Actualiteit

{kind=link}
Jan Clavaux - 22 aug 2017 - 12:48
Is prima Jan en van het Nationaal Archief een leuk initiatief (experiment)
Vr. groet
Everardus
Everardus Rollema - 22 aug 2017 - 16:56
Als ik het goed begrijp, kun je thuis zelf ook kosteloos met dat programma aan de slag: https://transkribus.eu/wiki/index.php/Main_Page
All services available in Transkribus are provided for free.
Transkribus is funded by the European Commission as part of the READ project.
Jan Clavaux - 22 aug 2017 - 17:06
Zou geweldig zijn, want het lezen van die oude teksten blijft voor mij worstelen.
niepoort - 22 aug 2017 - 21:11
In het stadsarchief van Leuven is men al een tijdje bezig met MONK.
Interessante links
Stadsarchief Leuven
GTB (De Geïntegreerde Taalbank): http://gtb.inl.nl/
MONK: Wat is MONK?
Leer MONK lezen!
Zie ook
http://www.itineranova.be/in/home
MVG-Paul
vap - 23 aug 2017 - 10:06
Ik las vandaag in de Volkskrant over transkribus, maar de handleiding vond ik niet erg duidelijk, want het lukt mij niet om met een bestand aan de slag te gaan. Heb wel een aantal files geüpload maar verder kwam ik niet.
Is hier meer info over het werken met transkribus?
Jan Meys1947 - 2 apr 2019 - 17:20
Als ik naar de Questions and Answers pagina ga en dan naar "Handwritten Text Recognition (HTR) Workflow", dan begrijp ik daaruit dat je eerst Transkribus moet leren om 'jouw' handschrift te begrijpen: eerst zelf 75 pagina's handmatig transcriberen. Daarna kan je het Transkribus team vragen om de 'training button' te activeren, zodat Transkribus jouw handschrift kan gaan leren.
Zie https://transkribus.eu/wiki/index.php/Questions_and_Answers#Handwritten_Text_Recognition_.28HTR.29_Workflow
Dit lijkt dus meer iets om met een team te doen voor een archief, bv een serie DTB boeken en niet om een enkel document te ontcijferen.
Als je googlet op 'archief' en 'transkribus', dan vind je meerdere archieven die al hiermee bezig zijn.
Fred van Deelen - 3 apr 2019 - 13:07
Zo lees ik het ook. Je (jezelf of als onderdeel van een team) moet een flink aantal vergelijkbare hand-getranscribeerde pagina's uploaden, welke zij gebruiken om een HTR model te trainen. Als ik het goed begrijp kun je dan alle modellen gebruiken die zij ooit getrained hebben. Het zou mooi zijn als het Nationaal Archief ook zo'n HTR model zou laten trainen. Wellicht bestaat deze al en kunnen we die gewoon gebruiken.
links:
https://transkribus.eu/wiki/images/7/77/How_to_use_TRANSKRIBUS_-_10_steps.pdf
https://transkribus.eu/wiki/index.php/How_to_Guides
Het is me niet duidelijk of je zo'n model ook kunt downloaden. (Als dat niet zo is, en ze halen hun website offline, dan zouden alle modellen weg zijn.) De bijbehorende software is blijkbaar wel allemaal open source: https://github.com/transkribus/
Een HTR model is blijkbaar gebaseerd op neurale netwerken (wiskundige algoritmen die je dus kunt trainen). Zie https://en.wikipedia.org/wiki/Artificial_neural_network voor wat meer informatie.
Ik zie dat ze bij het Amsterdam Archief bezig zijn om van het Amsterdams Notarieel Archief een HTR model te maken: https://velehanden.nl/projecten/bekijk/details/project/amsterdam_correct_notarieel_transkribus (of wellicht meerdere modellen).
WilbertD - 3 apr 2019 - 23:23 (laatst bijgewerkt 3 apr 2019 — 23:44 door auteur)
Het zou mooi zijn als het HTR Model wat door Vele Handen voor de gemeente amsterdam wordt opgebouwd, ook in het publieke domein beschikbaar zou komen.
Dan kan iedereen ervan profiteren.
A van Egmond (nieuw) - 4 apr 2019 - 06:49
Plaats een reactie
Om reacties (en nieuwe onderwerpen) te plaatsen op het Stamboom Forum dient u eerst in te loggen! Nog geen lid? Registratie is gratis en snel!
Bedankt, uw melding is verstuurd aan de moderators.